趣味の話
この記事は、mast Advent Calendar 2020 の1日目の記事です。
どうもこんにちは、mast N 年のはっしーです。
3年wとか4年…とか今年は結構適当に名乗ってきたけど実際のところ今年の僕は何年なんだ
— はっしー(BB) (@Hasshi7965) 2020年9月28日
自己紹介
軽く自己紹介すると、ちょっと機械学習に興味あるけどやったことないみたいな人に、自分の素人知識をひけらかすのが趣味です。
Akira Hashimoto (MAST17) @Hasshi7965
— MAST17→20 (@mast1720) 2020年5月1日
好成績をとると賞金をもらえる可能性があるので、データ分析コンペなどに参加している。落単芸人#MAST1720 pic.twitter.com/TWqdTqV6ua
趣味が上の通りなので、データサイエンス系のハッカソンにたまにいます。Peakersとか peakers.jp
はじめに
1年ぐらい前には、1-2dayで超短期のデータサイエンス系オンサイトハッカソンがかなり流行っていたのがコロナで中止になってたわけですが、夏頃に参加したZoom上でのオンラインハッカソンが今後は増えてくると思ったので、入賞してアマギフもらう方法みたいなのをこの機会に共有しておこうかなと思います。
※主にPeakersのハッカソンでの話になります
データサイエンス系ハッカソンってなんぞ?
まずデータサイエンスとは何かという話からすると、
データサイエンスとは、多くの学問領域にわたる科学的手法、プロセス、アルゴリズム、システムを使い、様々なデータから知見や洞察を引き出そうとする研究分野です。 データサイエンスという言葉自体は新しいものではありませんが、インターネットの普及やIT・科学技術の発達、AIの発展などにより、ビッグデータと呼ばれる膨大なデータも効率よく取り扱えるようになったことで、近年その注目度や関心度が増々高まっています。そして、ビジネスのみならず、医療や教育など、様々な場面でデータサイエンスは多くの価値を生み出しています。 データサイエンス | データサイエンティスト | データアーティスト株式会社 | AI (人工知能)
らしいです。
有名なPlatformとして、kaggleとかがあると思います。 www.kaggle.com
このkaggleとかで通常2-3か月ぐらいのスケールでやっていることを、オンサイトやzoom上だったりで顔を晒しながら1-2日の超短期でやるのがデータサイエンス系ハッカソンだと思います。
多分 #データサイエンス興味ある強い学生と繋がりたい みたいな企業が顔が見える状態(※多分重要)で学生の興味を引きたいというような需要でやってるんだと思います。
参加者の話
彼を知り己を知れば百戦殆からずと孫子も言っているので参加者の話をします。 参加者数は大体30人前後のことが多いです。※この中で3位ぐらいに入ればアマギフもらえると思うので上位10%と考えるとスマブラのVIPよりもよっぽど楽ですね。
参加者の分布を文字だけで説明するのは大変なのでグラフにしました。
ソースはハッカソンの終わった後に他の参加者だったり開催企業の人と話す時間があったりするのでそこでの僕の体感です。(※ 学年は低年齢マウントのために重要な要素なので僕は大体聞きます。)

主な層として学部2-3年と修士1年が主になってくる感じがします。とはいえ、学部1年も普通に居て表彰されてるの見たことあります。 僕自身は過去に4回ぐらい参加しているのですが、博士の学生は1人しか見たことがないです。
普通のkaggleとかだと社会人(※強い)も多かったり、そもそもの参加者が多いので賞金圏に入るのは至難だと思いますが、この手のハッカソンだと参加者がかなり限られるので、小遣いをもらいやすいことがわかります。
計算環境
データサイエンス系ハッカソンでは機械学習をすることになります。 機械学習をするには計算資源が必要ということを気にする人もいると思いますが、結論から言えば自前の計算資源を気にする必要はないです。
理由としてはgoogle colabolatoryで動くことが条件になっていたり、非公開データでのハッカソンとかだとデータの持ち出しを防ぐために主催企業に用意されたサーバー上で動かすことになるからです。
スケジュール
1-2dayのハッカソンがkaggleと一番違うのはここだと思います。
時間の表の作り方よくわからなかったのでとりあえず、積み上げグラフにしました。
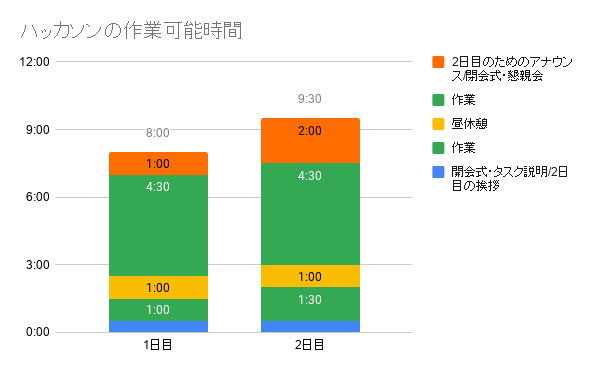
10時集合18時解散の間に結果の集計や発表、昼休憩などを挟むので特に1dayだと作業時間は6時間ぐらい、2dayでも11時間ぐらいです。この時間の間にデータを見て、特徴作って、モデルを学習させて、提出用のファイルを作ることになります。
ハッカソンが始まって以降のスケジュールはみんな一緒なので時間の長さ自体は重要ではないです。しかし、より多くの特徴を作れた人がより高い成績を残す傾向にあるので、時間が短いほどに事前の準備が大事になってきます。
事前準備
ハッカソン参加前の準備を列挙していきます。
- ハッカソンでのタスクに見当をつける
- 似ている過去問を読む
- 使う予定のライブラリのドキュメントを読む
- 必要そうな処理を先に書いておく
ハッカソンでのタスクに見当をつける
事前準備に充てられる時間には限りがあるので、どんなタスクに取り組むことになるのか見当をつけて効率的な準備をしたいところです。妄想力が問われます。 妄想する内容としては - 分類か、回帰か、はたまたランキングか - 自然言語を扱うのか - 時系列データを扱うのか - 地理情報を扱うのか などなど、無限にあると思いますが、自分の妄想した内容に沿って準備していくことになると思います
似ている過去問を読む
実際のところこれが一番重要です。 完全に初見のタスクを行うとすると効果が微妙な特徴を大量に作ることになりますが、過去問を読んでおけば似たタスクの時に効いた特徴を流用することで効果の高い特徴から作っていくことができます。
使う予定のライブラリのドキュメントを読む
自分の使うライブラリにどんなメソッドがあるのかは一度確認しておく必要があります。知らないメソッドは使えません。(1敗) 特にscikit-learnはできることが幅広いので知っていればと1行で済む処理を20-30分程度かけて書くことになります。(実体験)
必要そうな処理を先に書いておく
作業時間中に書くコードを減らすために、いつもセットで行う処理はまとめたものを先に書いておくといいです。 ハッカソン用によく使うライブラリのラッパーをまとめたオレオレライブラリを用意している人もいます。
モデル選択の話
作った特徴が効くかどうかは結局のところ学習させてみない限りわからない(※ もちろん、特徴同士の相関係数とかを見てある程度の予想はできるけど完全ではない)ので、学習自体に時間がかかるモデルを選択すると作れる特徴の数が少なくなって負けます。そのため、実質的に採用できるモデルは限られます。基本的には以下の3つのモデルから選ぶことになります。 - LightGBM - XGBoost - CatBoost ※ みんなが好きな深層学習は1-2dayのハッカソンには不向きだと思います。学習に時間がかかる&不安定なので
この3つは勾配ブースティング決定木と呼ばれるモデルで、使いやすさ、学習時間、精度のどれをとっても現環境最強だと思います。文句なしのSティアです。 他のモデルを試すのは、何も手がないけど時間だけはあるみたいな状態になってからでいいと思います。
このモデルを知らないがために、線形回帰やロジスティック回帰で挑んできてわからされる参加者とかも多いのでこれだけは知っておく必要があると思います。
結び
モデル選択で遊ばないでコード類を準備しておけば1-2daysのハッカソンで入賞することは難しくないと思います。短い期間でちゃんと実験する時間もない、たまたま作った特徴が当たるかどうかの実質運ゲーみたいなものなので、kaggleとかよりも上振れしやすいです。
とはいえ書いていて思ったのですが、的を得た準備をするためには結局ある程度の知識が必要っぽい気がするので、その辺は経験者が有利になる感じのゲームバランスしてそうですね。
データサイエンス系ハッカソンやkaggleに興味が出た人がもしいればkaggle本を読むことをお勧めします。

※ ろくに記事を書いていないこのブログは当然アソシエイト審査出してないです。それで、このリンクのアソシエイト報酬ははてなブログが受け取るようになっているらしいです。